

In today’s data-driven world, making sense of vast amounts of information stored in databases is crucial for businesses. Traditional database querying often requires knowledge of SQL syntax and table schema. However, with the advent of natural language processing (NLP) and powerful AI models, we can enhance the querying experience by enabling users to interact with databases using their natural language. In this blog, we will explore the concept of retrieval augmentation with BigQuery, leveraging OpenAI’s capabilities to generate SQL queries based on natural language questions. Before moving further let’s understand retrieval augmentation.
What is Retrieval Augmentation?
The large language model operates based on the information it was trained on, which is frozen in time. The training data is extensive and contains a wealth of information. However, retraining the model with new data is a costly and time-consuming process that is not frequently done. So, how can we address this issue? One approach is to use retrieval augmentation to keep the model’s knowledge up to date.
Retrieval augmentation involves retrieving relevant information from a knowledge base (here it is BigQuery Table Schema) and incorporating it into the large language model’s input prompt. This external knowledge base acts as a window into the world or a specific domain that we want the model to have access to. Instead of training the model with this new information, we utilize it during inference by providing it as part of the input, allowing the model to leverage the updated knowledge while generating responses.
Demo
The below demo is on fake simulated HR data. OpenAI is just aware about Schema not the actual data.
How it all works?
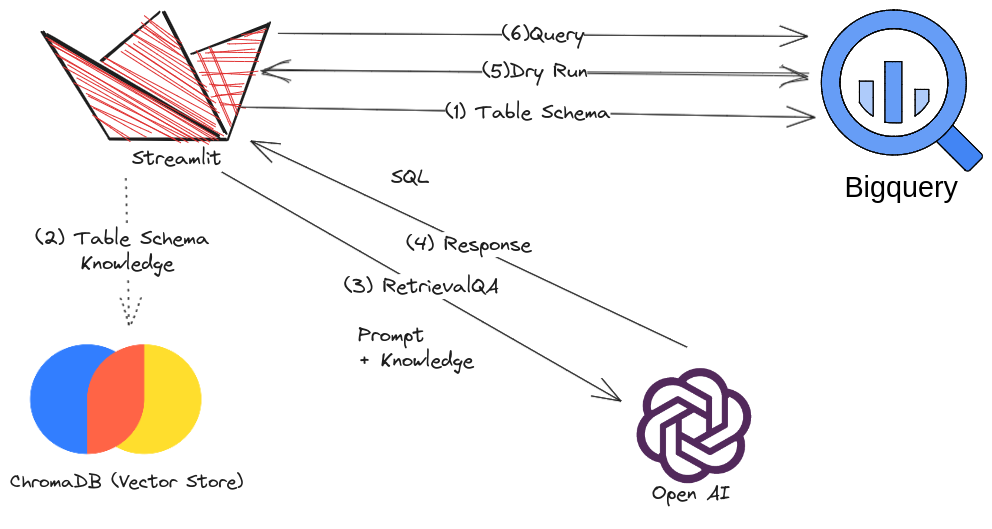
- Understanding BigQuery Table Schema: To begin, we need to familiarize ourselves with the structure of BigQuery tables. BigQuery provides a schema that defines the fields, their corresponding data types, and optional field descriptions. We can access this schema programmatically using the BigQuery API or client libraries.
- Building a Knowledge Vector Store: To enable OpenAI to understand the table schema and use it for generating queries, we need to extract the relevant information from the schema and store it in a knowledge vector store. This store acts as a repository of structured information.
- Utilizing OpenAI API for Query Generation: a state-of-the-art language model, can be employed to generate SQL queries based on natural language questions. By feeding OpenAI with the extracted schema details from the knowledge vector store, we can enhance its understanding of the database structure and improve query generation accuracy.
- Generating SQL Queries: When a user inputs a natural language question, we pass it to OpenAI via the API. With knowledge of the table schema, it can compose a SQL query that aligns with the intent of the question. The generated query is returned as a response.
- Executing Queries on BigQuery: The generated SQL query can be executed directly on the BigQuery database using the appropriate client libraries or APIs. The result of the query is obtained and presented to the user in a meaningful format, such as a table or JSON response. We can first hit the BigQuery Dry Run API to know how much data will be processed, or are there any syntax error in the Query. Running SQL queries generated by LLM without validation can lead to incorrect or potentially harmful results. To mitigate this risk, it is essential to incorporate measures to ensure the logic and validity of the generated queries. Here are a few strategies to avoid erroneous queries:
- Query Validation: Before executing a query generated by LLM, perform thorough validation to ensure its correctness. This can involve checking the syntax, structure, and semantics of the query. You can use SQL parsing libraries or tools to validate the generated queries against the known table schema and expected query patterns.
- Limit Query Complexity: Establish constraints on the complexity of queries that LLM can generate. Define boundaries on the number of tables, joins, subqueries, or other advanced SQL constructs allowed in the generated queries. By limiting the complexity, you can mitigate the risk of generating queries that are difficult to validate or execute correctly.
- Provide Examples to LLM on Valid Queries: Provide it with a dataset of valid and verified SQL queries. By exposing the model to a wide range of correct queries, it can learn patterns and increase the likelihood of generating valid queries during inference.
- Incorporate User Feedback and Iterative Improvement: Enable a feedback loop where users can provide feedback on the generated queries and their results. By collecting user feedback and iteratively improving the query generation process, you can enhance the accuracy and reliability of the generated queries over time. This user feedback loop helps identify and correct any inconsistencies or incorrect query logic. This step is like we are giving the LLM long term memory.
- Query Execution Sandbox: Consider executing the generated queries in a controlled environment or sandbox or sample data, separate from the production database. This allows you to assess the query results and identify any anomalies or issues without affecting the live data. Running queries in a sandbox environment provides an additional layer of security and allows for further validation before executing them on the actual database.
- Benefits and Applications: Retrieval augmentation with BigQuery and GPT-3 opens up new possibilities for intuitive and efficient data exploration. Some benefits include:
- Natural language interface: Users can interact with the database using their own words, eliminating the need to learn SQL syntax.
- Increased productivity: The query generation process is automated, saving time and effort.
- User-friendly data access: Non-technical users can easily retrieve information from the database without relying on SQL proficiency.
- Considerations and Challenges:
- While retrieval augmentation offers exciting prospects, there are some considerations and challenges to address, such as:
- Accuracy and query optimization: Ensuring that the generated queries are accurate and optimized for performance.
- Handling complex queries: Supporting more complex queries beyond simple retrieval tasks.
- Security and access control: Implementing appropriate measures to safeguard sensitive data and enforce access controls.
Retrieval augmentation with BigQuery and OpenAI provides a powerful solution for enabling natural language querying of databases. We can bridge the gap between users and databases, empowering them to obtain valuable insights with ease. The combination of BigQuery’s data warehousing capabilities and Open AI’s language understanding opens up new frontiers in data exploration.
To implement retrieval augmentation with BigQuery or any Warehouse solution and OpenAI effectively, partnering with a knowledgeable and experienced company like DataSlush can be highly beneficial. DataSlush specializes in data analytics and AI solutions, and their expertise can support you throughout the setup process. Here’s how DataSlush can assist you:
- Consultation and Solution Design: DataSlush’s team of experts can understand your specific requirements and use cases. They will work closely with you to design a tailored solution that aligns with your business objectives.
- Data Warehouse Integration: DataSlush will assist in integrating BigQuery into your existing infrastructure. They will help set up the necessary connections, access controls, and authentication mechanisms to ensure secure and seamless data retrieval.
- Knowledge Vector Store Implementation: DataSlush will guide you in building the knowledge vector store to store the table schema details. They will help extract the relevant information from the Data Warehouse schema, transform it into a suitable format, and design an efficient storage mechanism.
- Iterative Improvement and Support: As you start using the system, DataSlush will provide ongoing support and maintenance. They will actively seek user feedback, analyze query performance, and continuously iterate on the system to enhance its accuracy and usability.
Resource:
- Fixing Hallucination with Knowledge Bases: https://www.pinecone.io/learn/langchain-retrieval-augmentation/
- LangChain is a framework for developing applications powered by language models: https://python.langchain.com/en/latest/index.html
